If I could pick one thing in ‘agile’ that people refuse to believe: it is that the stories they are working on could be smaller and simpler. I am a believer though. A good thing for us all otherwise this article would get very awkward, very quickly. I know of a number of ways in which I can reduce the size of the stories my teams are working on. Today I’ll show you four. Before I show you these techniques, let’s recap why we would want to make stories smaller.
Why do we split stories?
If your answer to this question is: “to make the story fit within an iteration”; then you’re missing the point. What happens here is that your stories trend towards the size of your iteration: an arbitrary length of time. We should be splitting our story to make it less complex, to help us deliver the most valuable parts first and, to give us the best chance of capitalising on emergent design.
1. Conjunctions
The first place I look is a conjunction that is used in a story. I went to the Wikipedia page for User Stories and took their first three examples:
As a user, I want to search for my customers by their first and last names.
As a non-administrative user, I want to modify my own schedules but not the schedules of other users.
As a mobile application tester, I want to test my test cases and report results to my management.
Each of these can easily be split into two. I won’t get into how terrible these stories are in other ways. I’ll do my best to correct them as I go.
As a shop owner, I want to search for my customers by their first name.
As a shop owner, I want to search for my customers by their last name.
As a non-administrative user, I want to modify my own schedules.
As a non-administrative user, I don’t want other users to modify my schedule.
As a mobile application tester, I want to test my test cases.
As a manager, I want mobile application testers to report meaningful results.
2. By Acceptance Criteria
Consider the following acceptance criteria:
Given the customer has one transaction account and one credit account
When the customer views their accounts
Then the screen should show the names and numbers of the two accounts sorted in account number order
Given the customer has more than 20 accounts
When the customer views their accounts
Then the screen should show the first 20 accounts (in account number order) only
The best place to start with acceptance criteria is, like stories, looking for conjunctions. The first criterion says that the names and numbers of our accounts are displayed and sorted. I would split this into two. The first delivers that accounts displayed in whatever order they are stored in. The second story sorts the accounts. Sorting might be trivial, it might be not. We can’t tell: are the account numbers entirely numeric or can they alphanumeric. Can they have leading zeroes? Do we sort by bank state branch (BSB) and then account number? Are we sorting in an ascending or descending order?
The second criteria is talking about pagination. I would pull this out into another story. I want to know how many customers will have more than 20 accounts, what is the distribution. How often do they log in online? Are we delivering ‘value’ for people who never use the site. Even if we are, I suspect that feature can wait. Let’s get that account page up, showcase it. Then we can then look at the performance or usability of lots of accounts and design a nice way to deal with it. Pagination doesn’t help people find what they are looking for, it just makes the page load faster.
So our single story is now three:
- Show accounts (where the most value is)
- Sort accounts (and be more specific about what that means)
- Apply pagination if required (or find some other way for the user to find what they are looking for)
The idea here is that we look at acceptance criteria and identify the sub features. Group them and then work out if we can deliver some groups separately.
3. Incremental Design
The easy divisions have been found. It’s time to dig a bit deeper into what we have been asked to do. Let’s say that we’ve been given the following wireframe:
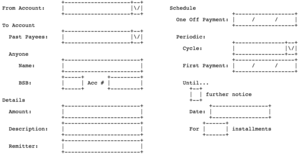
There has been a business decision to not release to production until all the features are implemented. This is where discussions about splitting stories end up. Why should we bother splitting the story if we have to deliver it all at once? Because we get value out of incremental design. Each part is delivered, we get feedback, improve on it and finally release the collective features as asked. There is a difference between being ready for release and deploying.
Taking the approach of building out the UI and then adding in the bits of logic and deferring integration is a bullish approach. A more considered path is to build the ‘pay anyone’ feature first. The smallest piece of work that slices through all layers and includes integration. We can demo this, get feedback and, iterate. After that: one off payment, future dated payment, open ended, etc etc.
What about batch processes or business intelligence work where there is often a sequence of extract-transform-load jobs before a final report is built. How about extract into a CSV and then let the business user look at the raw values. Then incrementally improve the quality of output before finally putting together the report. Or, rather than creating an open-ended platform for the analytics team to use. Find out what’s the next question the business wants an answer to. Go build that.
4. Reduce technical complexity
Another pattern I see is when the story can’t be any smaller due to the technical effort required. This is especially the case for any story played in the first few iterations. For this I take an approach I call ‘No frills or bells and whistles’.
On the whiteboard I create a column containing each of the steps that we have to take. In our example we’ve been asked to build a mobile, offline Wikipedia app. Our story might be “As a traveller I want to read an article so that I can learn about the place I am visiting”.
The steps are: download data, build the index, searching and search results and, displaying the results. The download is a challenge because a cut of wikipedia without images and history is about 9GB in size. The top 2 million articles is about 3GB. We’ll have to deal with stopping and starting the download. Or, running out of space, etc. We shouldn’t play a ‘download’ story because that doesn’t deliver anything useful to showcase.
On either side of this column are two more columns. The leftmost is labelled ‘No Frills’ and the rightmost is ‘Bells and Whistles’.
| No Frills | Process | Bells & Whistles | ||
|---|---|---|---|---|
| Manual copy from computer to device | Embedded in package | download data | Restart failures | auto-sync |
| alphabetic | subject index | build the index | tailored index | |
| no search | exact match only | search & results | partial match | fuzzy matching |
| no formatting | basic formatting | display page | multiple orientations | custom styling |
The team then brainstorms how to do each of the steps more simply. Sometimes this results in shiny new features. We put them on the right hand size. The shinier they are the more to the right they go. When we find a simplest solution, we put it on the left most column. After such a session we might end up with the following:
No Frills Process Bells & Whistles
Manual copy from computer to device Embedded in package download data Restart failures auto-sync
alphabetic subject index build the index tailored index
no search exact match only search & results partial match fuzzy matching
no formatting basic formatting display page multiple orientations custom styling
We take the leftmost column as how we will implement the first story. In this case we’ll manually copy the data on to the device. We’ll display an alphabetic list of records with no searching allowed. Each article displayed will just have plain text without formatting. It’s not a going to shift a million units. But you can build that quickly, demo it, get feedback and then start picking up new stories to play.
One of the benefits of this approach is that your other stories are also small boxes. You can even visualise progress by colouring in the boxes as you progress.
⁂
With any story, if you want to split it, you need to have a conversation with your product owner beforehand and the new stories should be estimated and prioritised accordingly. Even if you still play the new stories immediately after the original story, you will still get benefits. We’re interested in incremental delivery and reducing complexity.